在人工智能浪潮席卷全球的當下,國內外的科技巨頭與初創企業紛紛投身于大語言模型的研發與部署,一場前所未有的“百模大戰”已然拉開序幕。在這場圍繞算力、算法與數據的激烈角逐中,一個新的趨勢正悄然興起——模型即服務(Model as a Service, MaaS),而與之緊密相連、作為其基石與燃料的“數據處理服務”,正迎來前所未有的機遇與挑戰。
一、百模大戰:從模型競賽到服務生態的演進
“百模大戰”的本質,是各大廠商在通用人工智能(AGI)賽道上的卡位競爭。從文本生成、代碼編寫到多模態理解,模型的能力邊界不斷被拓展。單純的模型性能競賽已逐漸顯露出瓶頸:高昂的研發與訓練成本、復雜的部署運維、以及模型與實際業務場景的“最后一公里”對接難題。這促使行業思考從“擁有一個頂尖模型”向“提供一套易用、可靠、可擴展的模型服務”轉變。MaaS模式應運而生,它將復雜的AI模型封裝成可通過API(應用程序編程接口)或平臺輕松調用的服務,降低了AI技術的應用門檻。
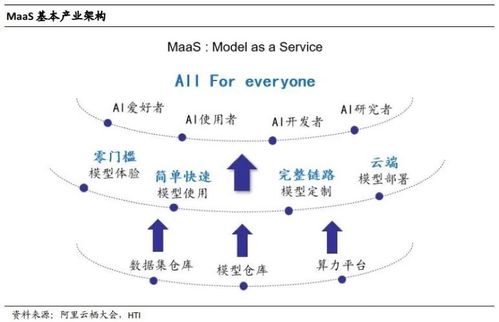
二、MaaS風起:數據處理服務成為關鍵樞紐
MaaS的成功,遠不止于提供一個訓練好的模型接口。其核心價值在于能夠持續、穩定、高效地服務于千行百業的具體需求。而這背后,高質量、專業化、流程化的數據處理服務構成了不可或缺的支撐體系。這股刮起的“MaaS之風”,實際上將數據處理從模型研發的幕后推向了服務運營的臺前,其重要性被提到了新的戰略高度。
1. 數據供給與精煉:MaaS的“糧草”保障
無論是通用模型還是垂直領域模型,其表現都嚴重依賴于訓練數據的質量與規模。專業的MaaS提供商需要構建持續的數據供應鏈,包括數據采集、清洗、去重、脫敏、標注等一系列服務。特別是在垂直領域,如金融、醫療、法律等,需要深度的領域知識進行數據標注與構建,這催生了專業化的數據服務商。數據處理服務確保流入MaaS管道的是“高品位礦石”,而非“原始泥沙”。
2. 數據飛輪與持續優化:MaaS的生命力源泉
優秀的MaaS平臺具備“數據飛輪”效應:用戶使用服務產生的反饋數據(如點擊、修正、評分)被安全合規地收集,經過處理后用于模型的持續微調與優化,從而使服務越用越智能。這要求MaaS平臺必須具備高效的數據回流處理、分析和再訓練能力。數據處理服務在此扮演了“循環凈化系統”的角色,讓模型能夠在實際應用中不斷進化。
3. 場景化數據工程:解鎖MaaS商業價值
企業用戶需要的不是一個“萬能但平庸”的模型,而是一個能精準解決其特定問題的工具。這就需要將通用模型與企業的私有數據、業務流程相結合,進行場景化的定制與微調。數據處理服務在這里延伸為“數據工程”服務,包括企業數據的合規接入、格式轉換、知識抽取、提示詞工程(Prompt Engineering)數據集構建等,幫助模型快速適應具體場景,實現從“能力”到“價值”的轉化。
三、數據處理服務的新形態與挑戰
在MaaS的驅動下,數據處理服務本身也在發生深刻變革:
- 自動化與智能化:傳統依靠人海戰術的數據標注正逐步被主動學習、弱監督學習、AI輔助標注等技術提升效率。
- 全流程與平臺化:出現了一站式的數據服務平臺,涵蓋從原始數據管理、標注工具、質量校驗到版本管理和交付的完整鏈路。
- 專業化與垂直化:在醫療影像、自動駕駛、科學計算等領域,需要極高專業壁壘的數據處理知識與標準。
挑戰也隨之而來:
- 數據安全與隱私合規:在數據流通與使用的各個環節,如何滿足日益嚴格的法律法規(如《數據安全法》、《個人信息保護法》)是首要課題。
- 質量與成本的平衡:追求極致的數據質量往往意味著高昂的成本,如何在可控預算內達到模型訓練與優化所需的“足夠好”的數據標準,是一大挑戰。
- 技術標準與工具碎片化:數據處理工具和格式尚未完全統一,給數據在不同平臺和模型間的遷移復用帶來困難。
四、展望:共建協同共生的AI新生態
“百模大戰”的下半場,競爭焦點將從模型參數的比拼,轉向以MaaS為載體的服務體驗、生態構建和產業滲透能力的較量。在這個過程中,數據處理服務將不再是一個獨立的、外包的環節,而是深度嵌入MaaS價值鏈的核心能力之一。 未來的贏家,很可能是那些能夠將頂尖模型能力、穩健的MaaS平臺與強大、合規、高效的數據處理服務體系有機融合的廠商。
一個由模型提供商、數據服務商、行業應用方共同參與的協同共生新生態將逐漸清晰。在這個生態中,高質量的數據處理服務如同流淌的血液,為整個AI產業注入持續進化的活力,推動人工智能技術真正落地生根,賦能百業千行。